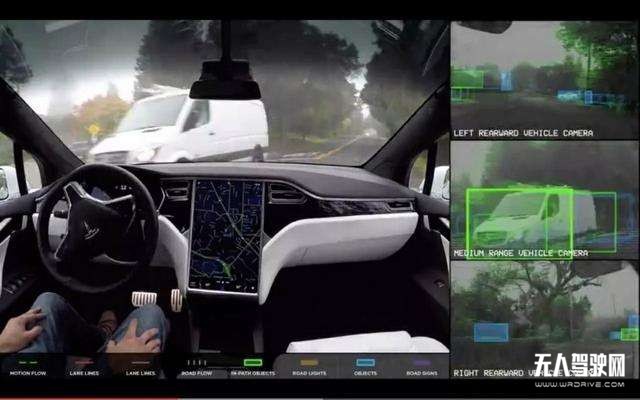
感知,包括了传感器融合(整合多传感器的数据)、物体检测(发现障碍物)、物体分类(障碍物是不是行人),物体分割(行人位于道路右侧还是左侧)和障碍物跟踪(行人在向哪个方向移动)等。
感知,是自动驾驶的前提,没有精确的感知,自动驾驶就是一场灾难!要做到精确的感知,必须采用多种探测技术,因为目前全世界还没有一种探测技术能适应所有场景。
常见的感知传感器主要有:视觉类成像传感器(包括单目/双目立体视觉、全景视觉、红外相机等)和雷达类测距传感器(包括激光雷达、毫米波雷达、超声波雷达等)。
在光照良好的条件下,可见光视觉类传感器就像人类的眼睛,可以提供最全面最准确的环境信息,但是在黑夜、雨雾雪等恶劣环境下,它们就无能为力了。红外传感器是近些年才被人们所重视的,能在任何环境或天气条件下较准确地识别到生物,但是对径向运动的辨别能力很差,没有角度测量能力,不能完成静止测距。
雷达类传感器一般不受天气或光照影响,但是它们不能精确地确定物体的大小和形状,只能确定在距离多远的地方有物体存在;有的雷达技术对部分材料敏感、对部分材料不敏感,可能会造成误判。
激光雷达传感器也是近些年比较火的技术,与其他的雷达类传感器不同,它综合了视觉传感器和雷达传感器的优点:能成像能测距、不受光照影响,但是也有缺点:成本很高、会受雨雾灰尘等环境因素影响。
前面说的这些感知技术,都是从车辆自身的角度来说的,是汽车采集环境数据的第一来源,但仅靠这些手段去实现高级别的自动驾驶还是不够的。我们在ITA视角第三期文章《车联网与5G和自动驾驶》里讲过,借助于车联网的V2X通信,汽车可以从周边车辆、道路、基础设施等获取到更多信息,大大增强汽车对周围环境的感知。通过这种方式,可以突破单车感知的局限性,降低单车传感器的成本,扩大单车感知的范围。
综上所述,汽车会通过自身安装的多个摄像头、多个雷达等传感器实时采集环境数据,也会通过V2X通信技术从周边车辆等获取环境数据,那么,这么多数据应该怎么处理呢?
首先,一个基本原则是,以汽车自身传感器采集到的数据为主,从周边车辆等获取到的数据为辅。因为,没有人愿意把自己的安危交给他人决定,万一周边车辆等传递过来的数据是过期失效、甚至是恶意篡改的呢?
其次,汽车自身采集的数据也有很多种,有的是2D图像数据,有的是3D激光点云数据,还有的是距离数据等。而且,不同种类的数据还会有多个来源,有的是车前方的,有的是车后方的,还有的是车两侧的。所有这些数据,有两种处理方案:集中式处理方案和分布式处理方案。所谓集中式处理,就是传感器只管产生数据,把产生的大量数据通过高带宽的总线传输到高性能的中央处理器,由中央处理器进行大量的运算处理;所谓分布式处理,就是传感器不仅产生数据,还要把产生的数据先进行预处理,然后再把处理后的少量数据通过总线传输到中央处理器,中央处理器只需要进行融合等少量的运算处理。
不管哪种方案,所有传感器的数据都需要进行深度融合,合成为包含多个角度、距离、维度的全方位的环境数据,然后在此合成数据基础之上再进行识别和处理,进行物体检测、物体分类,物体分割和障碍物跟踪等。
除了需要感知,汽车还需要定位和高精度地图。有了定位和地图,才能知道我在哪里、目的地在哪里、怎么去目的地。地图好说,有专业的公司专门负责制作和维护,那么定位怎么弄呢?一般有三种方法:
1、基于地标定位。根据视觉传感器或者激光雷达传感器采集到的图像,与数据库中的特征进行匹配,确定车辆的位置。
2、基于信号定位。车辆安装GPS和/或北斗,获取卫星定位信号;还可以通过4G/5G的蜂窝通信系统基站定位。
3、基于惯性定位。首先知道车辆的起始位置,然后根据惯性传感器来的数据计算车辆当前的位置和方向,本质上就是在初始位置上不断累加位移矢量来计算当前位置。
通常情况下,使用最多的定位方法,是2、3两种方法的结合,即卫星定位+惯性导航。而在自动驾驶中,为了保证高准确度,往往采用1、2、3三种方法结合,即先使用卫星定位+惯性导航先判断出大概位置,再使用高精度地图与感知系统获取到的图像进行对比计算,确定出更精确的位置。
最后,有了对当前周边环境的感知,有了定位和地图,那么就可以通过大量复杂的计算,制定出车辆的运动轨迹和行为动作,也就是规划与决策。为了保证自动驾驶的安全性和舒适性,对算法就提出了很高的要求:速度要快,要能对动态的大量数据快速计算出结果;结果要合理,稍有差错可能就造成严重的后果;算法要智能,能自动学习,能正确处理各种未知的突发情况。
在以前,传统的编程模式是穷举式的,典型的就是if...else if...else这种结构,把所有已知情形都列举出来并一一给出处理办法,然后其他所有未知的都归并到else这一个地方给出一个笼统的处理办法。以这种思路写出的程序如果用于自动驾驶,可能会出现什么样的结果?大家自己可以想象。
随着技术的发展,神经网络理论逐渐成熟,科学家基于对人类大脑神经细胞、学习和条件反射的观察和研究,建立并完善了深度学习的算法模型。与以前算法最大的不同就是,它是基于大量数据训练逐步自己完善自己的,而不是由开发者事先确定好的。甚至模型中的很多参数,开发者自己都不能解释为什么应该是这个值而不是其他值。
很多人在上大学时可能都干过这样的事:做实验,自己的实验没做好,结果不理想,于是从别的同学那里抄来结果,然后开始修改自己的实验中间过程数据,让数据能跟结果看起来吻合。深度学习算法本质上也是这样做的:原始输入数据和对应的最终结果都有了,算法开始自己拼凑公式中的参数,以使能根据输入数据计算出相同的结果;然后换一批输入数据重复相同的过程,拼凑出的参数既要保证本次计算能得出正确的结果,还要保证以前的数据也还是能得出正确的结果;重复这样的过程,直到所有数据都训练完,这样最终拼凑出的参数模型,能保证所有已知数据都能计算出相应的正确结果。样本数据越多,拼凑出的参数模型越能接近反映事物的本质。
实践已经证明,这种解决问题的思路,要比从探究事物本质原理的角度建模写算法要好,简单、粗暴、有普适性。但是,毕竟是拼凑出来的,只能是尽可能地接近事物的本质,而不能保证100%就是事物的本质。
当前自动驾驶大部分是在L3级别的,叫有条件自动化,对方向盘和加减速中的多项操作提供驾驶支援,其他的驾驶操作由人类驾驶者完成。
L4级别是高度自动化,由无人驾驶系统完成全时驾驶操作,根据系统请求,人类驾驶者不一定需要对所有的系统请求做出应答,限定道路和环境条件,这是后面几年人们的研发重点。
L5级别是完全自动化,允许车内所有乘员从事其他活动,无需对车辆进行监控。这是人们追求的目标,什么时候能实现?也许十年,也许二十年。但真到了L5普及的那一天,你敢用吗?我觉得汽车的安全防护技术要有重大突破,即使自动驾驶决策失误,也不能造成非常严重的后果,这样人们才能安心地将自己的安危完全托付给汽车。