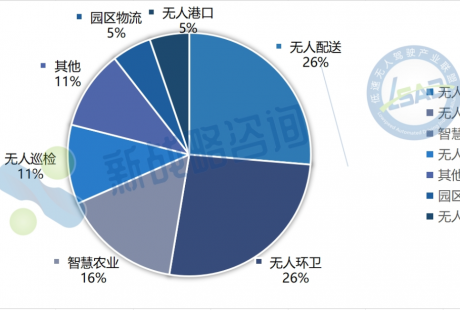
行为预测到底重要在哪?
在行驶过程中,自动驾驶汽车恐怕要一直回答这个问题——「我周边的车辆、行人与自行车在未来 5 秒内会做什么?」
这个问题的学名叫「行为预测」。
行为预测到底重要在哪?
自动驾驶公司 Pronto CEO Anthony Levandowski 讲述了自己的看法:他认为自动驾驶原型车在「预测」能力上的短板是阻碍其奔向 Level 4/5 的绊脚石。
在 Medium 上发布的一篇博文中,Levandowski 写道:
「现在没人能实现 Level 4/5 是因为如今的软件还不太行,它无法预测未来。在这方面,软件跟人类直觉差远了,而行为预测又恰恰是道路安全最重要的因素。」
在 TechCrunch 的采访中,Levandowski 又重申了这一观点:
「如果你想分析测试车每次『脱离』背后的故事,找到真正的原因,最终结果都是软件故障。即使是较为成熟的公司也难以避免,因为在复杂环境下,车辆很容易出现误解或沟通问题。眼下我们的问题不是能否找到更好的传感器,而是如何解决预测这个大问题。」
另一位持有相同观点的是 Chris Urmson。2013-2016 年他是 Waymo 的实际掌舵人,现在则是自动驾驶公司 Aurora 的 CEO。
在最近的一次采访中,Urmson 告诉麻省理工助理教授 Lex Fridman:
「如果我有魔杖,会用魔力提升系统哪部分,好加速自动驾驶技术落地呢?当然是车辆的感知预测能力。也就是说,如果明天你能给我一个完美模型,告诉车辆刚才发生了什么,现在什么正在发生和未来五秒将发生什么,情况将大不相同。」
数据越多其准确度就越高?
Waymo 和特斯拉这样的头部公司正试图用深度学习来解决行为预测问题,即用数据集训练深度神经网络。
对深度神经网络来说,数据越多其准确度就越高,因此各家公司都开启了疯狂「投喂数据」模式。
特斯拉 AI 主管 Andrej Karpathy 就在今年 3 月的 Autonomy Day 上讲述了特斯拉是如何玩转深度学习的:
在类似目标探测的深度学习应用中,许多公司都会遭遇瓶颈,因为他们需要花钱请人手动给图片或视频加标签。
拿目标探测举例,灌入神经网络的数据可能是视频中包含了行人的一帧画面,而各家公司想要的输出是自动打上「行人」这个标签。
当然,训练神经网络也同样是一个劳动密集型工作。
想通过训练得到这样的效果,就得给神经网络持续输入成千上万张类似图片,并且在画面中标出哪些是行人,而这个打标签的过程全靠人手工完成。
有了行为预测,再加上过去 5 秒对周边车辆动向的输入数据,输出端可能就会给出未来 5 秒对周边环境变化的预测。
这 10 秒钟的记录会成为你手上的输入-输出对,是训练深度神经网络的上好「养料」。至于人工打标签,则完全没有必要。
采用行为预测这种方法后,你甚至不用上传视频,车辆能直接保存一段周边环境的抽象记录,而在自动驾驶系统看来,这段抽象记录其实与人工打上的标签并无二致。
在行为预测上,特斯拉的优势就在于那每天奔忙在路上的 50 多万辆电动车——这样车辆搭载 Autopilot 的第二代和第三代硬件。
也就是说,特斯拉用车上搭载的 8 颗摄像头、前置雷达、神经网络计算机搞定了车辆行驶途中的数据记录,这些数据还能通过 Wi-Fi 回传给特斯拉。
想象一下,如果这 50 万辆车回传的都是抽象记录而非原始视频,特斯拉的行为预测训练数据库得有多强?
当然,车辆获得的数据也不会一股脑都塞给车队,筛选是个必要的过程。
举例来说,将行为预测神经网络犯的错当训练数据就非常有意义,而这个纠错的过程是个进步的捷径,比投喂各种随机数据有效多了。
简而言之,数据在精不在量。
从「长尾理论」的角度来看,即使做出错误行为预测的几率很低,比如每 100 万英里一次,特斯拉的车队每个月行驶 10 亿英里也能拿到 1000 个「反面典型」。虽然这 1000 条数据量不大,但绝对价值连城。
算力的提升可助推神经网络的性能
虽然整个行业都如打鸡血一般,但谁也不敢肯定全自动驾驶到底什么时候才能实现,也许明年就能成,也许十多年后才能落地。
不过,华尔街巨鳄们相信,一旦全自动驾驶普及,自动驾驶打车行业会大行其道,最终孕育出一个年营收破万亿的超级市场。
如此巨大的诱惑之下,大家都打破头要深耕深度学习、神经网络和行为预测。

ARK Invest 的金融模型预计,如果特斯拉如 Musk 所言,明年实现全自动驾驶,从长期来看特斯拉股价涨上 20 倍都没问题。
即使一分进账都没有,通用旗下自动驾驶部门 Cruise 估值依然高达 190 亿美元。
去年 8 月,摩根士丹利更是大胆给了 Waymo 1750 亿美元的超高估值。
今年,投资银行 Jefferies 则直接抛出 2500 亿美元的新价码,称未来十年内 Waymo 就能站上这一台阶。最近更是有消息传出,称 Waymo 有意寻求外部投资者,其估值顶的上好几个 Cruise。
如果说行为预测真的是自动驾驶最难且最重要的问题,特斯拉在这方面还领先 Waymo、Cruise 等公司的话,那么特斯拉在自动驾驶出租车和自动驾驶卡车市场上必然前途不可限量,其股价也应该大大超过 Waymo 或 Cruise(现在特斯拉市值仅 420 亿美元)。
即使全自动驾驶永远也实现不了,特斯拉在半自动驾驶市场也能玩的风生水起。
现在特斯拉已经上线 Navigate on Autopilot 与增强版召唤等功能,如果加上未来新的半自动驾驶功能,足以让特斯拉旗下电动车有自己独特的辨识度。
如果其他公司无法搭建像特斯拉一样的数据采集车队,在深度学习上想与 Musk 竞争完全是痴人说梦,而深度学习的「深度」则决定了半自动驾驶技术先进与否。
一直以来,许多评论家都认为特斯拉只不过是一家电动车公司,只要竞争对手们肯用功,早晚能拿出更棒的产品。
事实上,Musk 眼光可没这么短浅,自动驾驶才是特斯拉真正的「护城河」。
从公司文化看,市场上的特斯拉「杀手」其实都是硬件公司。
举例来说,2012 年特斯拉就开始进行的 OTA 升级,这些汽车厂商们现在才开始追赶。从长远来看,这也是特斯拉保持竞争力的一大动力来源。
据 Elon Musk 介绍,当下特斯拉的神经网络与其他自动驾驶相关软件其实只是占据特斯拉新型定制芯片 FSD 5%-10% 的算力。
鉴于算力可助推神经网络的性能,因此未来特斯拉还会继续进行挖潜。
在去年第三季度财报电话会上,特斯拉 AI 主管 Andrej Karpathy 就表示,更强大的神经网络已经在路上,FSD 是其坚强后盾。
最近,Musk 也在推特上指出,今年第四季度开始,搭载 FSD 的车型在功能性上会逐渐甩开其他车型。
在懂行的人看来,Musk 什么时候将 FSD 的性能压榨到极限,特斯拉就要迎来新阶段。
鉴于 Karpathy 在公开场合频频释放信号,想必特斯拉新的神经网络已经秘密开发多时。
这颗「小核弹」不但体积更大,架构上肯定也得到了优化(比如升级了人工神经元和连接方式)。
对特斯拉来说,性能上的几何级提升是其对神经网络的最大期待。
如何将视觉、预测与模拟编织在一张网里?
如果计算视觉神经网络没能探测到路上的一辆车,处在下游的行为预测神经网络也同样会对这辆车「失明」。
同样的,这个流程产生的抽象记录质量也会变差。所以无论是训练还是推理,计算视觉的提升就意味着行为预测的进步。
这样的道理也适用于模仿学习,而特斯拉就在用这项技术进行路径预测。
在模仿学习过程中,神经网络会「吸入」一些输入数据,它可能是原始视频,但恐怕更像计算视觉神经网络生成的抽象记录。
整个神经网络通路走下来,大家想在输出端得到车辆下一步该采取什么行动的指示,随后这些数据会被传输至控制软件以决定到底该下什么命令(刹车、转向还是加速)。
借助成千上万特斯拉车主,特斯拉能采集到丰富的输出数据。这些数据与抽象记录相结合,就能生成训练所用的「输入-输出」。
在模仿学习中,这个「输入-输出」对其实就是「状态-动作」,它包含了世界或周边环境的状态,以及人类驾驶员的动作。
与行为预测类似,模仿学习的「输入-输出」对也无需人类对数据进行手动标记。
有了充足的「状态-动作」对,神经网络就能从人类驾驶员那里学到状态与动作间的联系。再加上充分的训练,神经网络就能自己找到发号施令的状态,从而学会驾驶。
如果在模仿学习中用到了抽象记录,那么训练和推理中计算视觉错误的减少,也意味着模仿学习错误的减少。
此外,提升行为预测能力也能促进模仿学习。
也就是说,模仿学习用到的输入数据并不一定非要来自计算视觉网络,行为预测网络也能贡献额外的输入数据。

ChauffeurNet 组成部分:FeatureNet 和 AgentRNN
Waymo 的模仿学习网络 ChauffeurNet 就遵循了这样的逻辑。
它将视觉、预测与模拟编织在一张网里之后,模仿学习就能有两个参考目标,学习起人类司机的动作就更高效了。
想要搞清环境状态与驾驶员动作之间的关联,模仿网络就得被置于与人类司机相同的环境下,并且获取相同的信息。
众所周知,人类开车不只靠视觉,我们还有很强的预测能力。
在自动驾驶系统中:
计算视觉网络负责重建人类眼睛看到的车辆外部环境;
行为预测网络则需要再造人类大脑中的整个预测流程。
两大网络的目的都是拿出正确的驾驶策略。
未来,自动驾驶汽车可能会直接从像素中获取相关信息,但眼下机器学习工程师还是倾向于将任务分配给视觉、预测和模仿。
因此,预测能力(作为输入)的提升也意味着模仿能力的提升,而视觉能力(作为输入)的进步则能让预测和模仿共同受益。
行为预测才是自动驾驶的终极杀器
在讨论数据采集时,许多人并不看好特斯拉的「超级车队」,因为他们认为特斯拉付不起人工打标签的钱。
可惜,特斯拉根本就没玩监督学习那一套,行为预测才是终极杀器。
除此之外,特斯拉还用上了模仿学习,而它不用人工打标签。
其实,即使选择用传统的监督学习研究计算视觉,特斯拉的车队也能带来各种价值连城的数据(包括各种极端情况)。
举例来说,用来识别马匹的深度学习网络也可以在车上运行,一旦它觉得马出现了,就能启动相机快速拍一张。显然,这种方法能用在识别相对稀有的物体上。
眼下,业界正在攻克计算视觉的自监督学习技术,有了它,训练信号就可以完全取自数据本身,无需人工标签。
据汽车之心了解,在深度感知领域,特斯拉已经开始试验自监督学习。
上述讨论可能有些晦涩难懂,不过特斯拉未来到底价值几何其实靠的就是这些技术。
面对自动驾驶这个万亿级别的市场,谁都想成为领军者。而这,意味着数千亿美元的估值。