

您现在的位置:首页 > 供需失衡,如何填补自动驾驶数据标注供需鸿沟?
供需失衡,如何填补自动驾驶数据标注供需鸿沟?

2022年,国内自动驾驶商业化进程迎来新的发展篇章。
相关统计数据显示,今年一月份,国内新车前装标配搭载L2级辅助驾驶系统上险量为48.45万辆,同比增长63.21%,前装搭载率22.13%,同比增长近10%。
目前,全国已开放道路测试里程超5000公里,发放测试牌照900余张。8月1日,《深圳经济特区智能网联汽车管理条例》正式生效,深圳作为先行示范区,完全自动驾驶汽车自此可合法上路。
可以说,自动驾驶产业在商业化方面交出了一份相当不错的答卷,此前预估的万亿产业规模正被市场逐步兑现。
而伴随着汽车产业智能化发展路径的逐渐明晰,市场需求也在倒逼自动驾驶公司进一步提升技术水准以及为消费者提供更优质的驾驶体验,在推进L3、L4级自动驾驶技术落地的路上,仍有众多问题亟待解决。
指数级增长的数据需求
自动驾驶技术属于人工智能的一个重要分支。
现阶段,实现人工智能主要以机器学习,尤其是深度学习方式为主。在实际应用中,无论是采用有监督学习模式,亦或是半监督学习模式,对标注数据均有强依赖性需求。
对场景积累度与感知能力要求更高的自动驾驶技术对数据的依赖度也更高。当下两种主流视觉感知路径,无论是特斯拉的毫米波雷达+摄像头解决方案,还是Waymo的高精地图+激光雷达解决方案,感知算法的训练与调优都离不开大规模的路测数据。
这些路测数据规模有多大,需要多少才能满足完全自动驾驶的需求,兰德公司对此的预估是,自动驾驶汽车需要在真实或者虚拟环境中至少进行177亿公里的测试,不断利用新数据调优算法,才能证明自动驾驶系统比人类驾驶员更可靠。

假设车队规模100辆,全年24小时无休并以45千米每小时的速度进行测试,大概需要500年。
500年的时间显然过于漫长了,最简单粗暴的解决方案是扩充车队规模。当车队规模达到1000辆时,时间周期可以缩短至50年,而当车队规模扩充至10000辆时,只需5年就可以完成所有的路测,并采集到相关的数据。
一个问题,如果有解决方案却没有付诸实施,则意味着该解决方案是不可行的。当下各自动驾驶公司在扩充车队方面均没有过于激进,显然,单纯扩充车队规模并不足以解决自动驾驶技术调优问题。
问题的根源在于如何处理这些路况数据。
基于深度学习算法的自动驾驶技术,绕不过数据的标注和训练。采集得到的路况数据均为非结构化数据集,这些原始数据集未经处理是无法直接用于算法的训练与调优。
开放路段下的自动驾驶汽车对于感知系统的实时性与安全性要求极高,与之相对应,相关算法的准确度与场景适应度也需要达到一个很高的水准,这就对数据标注的规模与数据产出质量提出了更高的要求。
换言之,自动驾驶技术进步带动了规模庞大的数据标注需求。但数据标注行业量产能力是否跟得上自动驾驶行业快速扩充的步伐呢?
答案是没有。
线性增长的数据供给
与指数型增长的自动驾驶数据标注需求相比,则是线性增长的数据供给。
数据标注行业发展早期,行业准入门槛较低,数据处理场景较为简单,算法模型尚处于实验室验证阶段,往往简单的标注工具+少量的数据即可满足需求。
但如此得来的算法模型过于基础,最终落实到真实场景仍需不停提升算法性能。
目前,提升算法性能的方式主要有两种,一种是提高算法模型的设计复杂度;另一种则是以数据迭代为中心,通过投喂海量数据以提升算法的性能。
从实践结果上来看,第二种方式更具优势,且被大规模采用。
提高算法模型的设计复杂度本质上依然离不开数据投喂,且针对特定场景设计算法仍旧需要特定的数据。
从算法发展路径来看,通用场景的泛化算法已经基本成熟,大多数新算法是在老算法的基础上发展而来。目前,一些成熟且得到大范围应用的算法模型架构在很多年前已经基本确定,后续算法迭代则主要以数据为主。
在实际应用去解决问题时,不同场景需要解决的问题不尽相同。这并不是算法模型的问题,而是场景适配度的问题。算法架构与技术路径并无问题,场景不同,需要处理的数据也就不同。
以自动驾驶场景为例,目前自动驾驶感知算法技术架构已经基本成熟,封闭场景如矿山、机场、港口等因场景较为固定且单一,算法迭代基本成熟,因此商业化发展之路较为顺畅,已进入实质商业化运营阶段。
而开放道路下所需要处理的场景过于复杂,仅简单一个路口所演化出的场景类别就堪称海量,算法模型迭代需要的数据量也呈指数型快速增长。
但数据标注行业长久以来粗放的执行方式以及依赖简单标注工具的业务执行方式,却无法在供给端快速满足市场的爆发性需求。
尤其随着自动驾驶3D点云数据的应用与普及,点云数据处理对数据供应商的产品力以及交付能力提出了更高的要求,传统SLG(销售驱动增长)重销售轻产品的模式在数据标注量产能力方面逐渐暴露弊端,数据标注行业供给侧与需求侧之间的鸿沟愈发被拉大。
供需平衡的关键
创新与变革是提升生产力的关键,数据标注行业亦然。
数据处理难度与处理规模的提升对产品力提出了更高的要求,传统以销售为核心驱动力的业务模式并不能构建起深度护城河,效率提升与成本降低的关键是技术创新与执行方式的变革。
作为行业领先的数据服务企业,曼孚科技长期聚焦自动驾驶行业,并对自动驾驶数据标注拥有自己的理解。
相较于SLG模式业务增长需要堆积人力的方式,曼孚科技回归科技创新本质,以PLG(产品驱动增长)模式代替SLG模式,重视塑造产品力,构建技术护城河。
产品方面,曼孚科技推出了第三代数据服务平台——MindFlow SEED 数据服务平台。相较于传统标注工具,SEED定位平台而非工具,原因在于SEED平台在解决数据标注问题的同时,也很好地解决了数据生命周期管理问题。
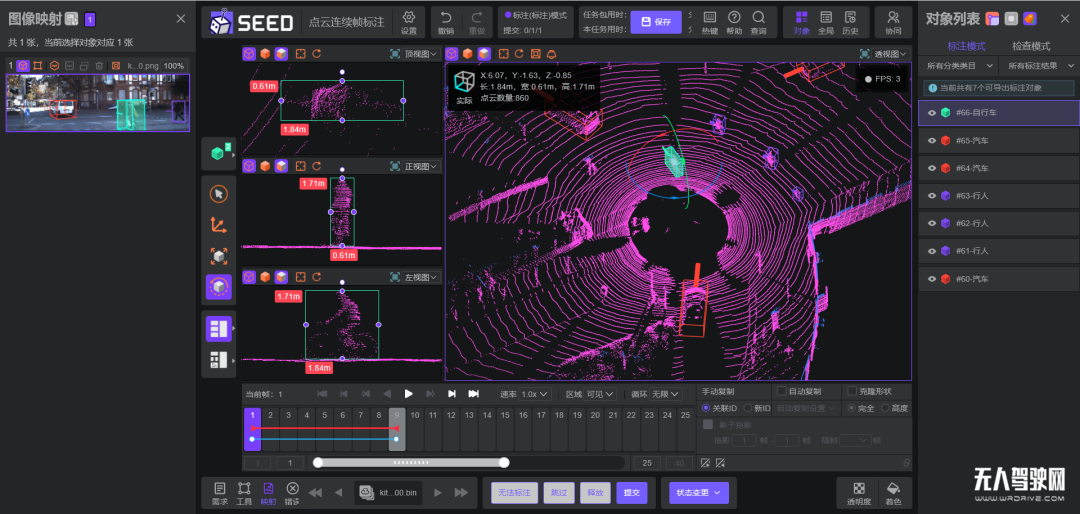
MindFlow SEED数据服务平台
借助AI算法驱动的自动标注,以及针对自动驾驶场景推出的布尔运算、融合点云车道线、自动关键帧等功能,MindFlow SEED 数据服务平台在数据处理尤其是自动驾驶3D点云数据处理方面建立了深厚的技术壁垒,平均标注效率提升10倍以上,并在业内维持了较高的技术领先性。
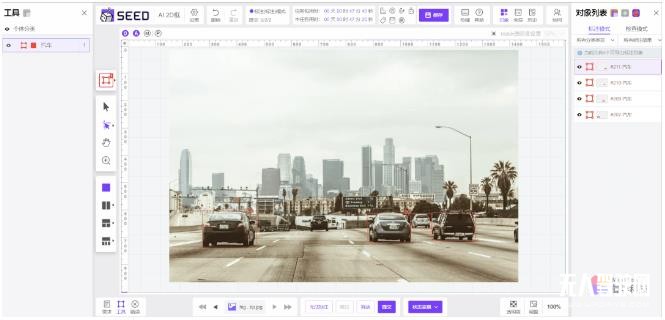
AI自动标注
而在数据生命周期管理方面,MindFlow SEED数据服务平台建立了一整套覆盖非结构化数据接入至结构化数据导出的管理机制,功能涵盖数据集管理、团队人员管理、工作流管理、数据统计分析等模块,流程周转更流畅,有效节约管理成本并显著提升业务执行效率。
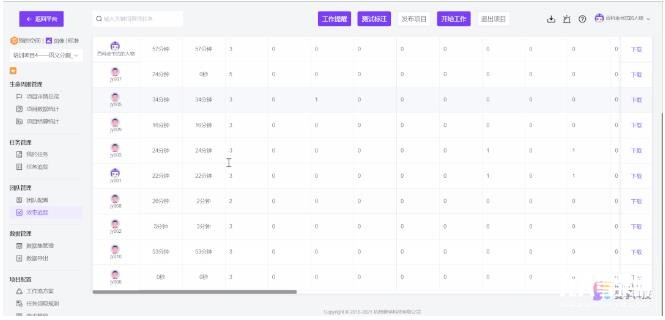
可视化统计分析
与传统依赖人力的业务执行方式不同,曼孚科技还更加注重自动化建设。通过提升RPA(自动化)水平,以平台产品取代过往人力堆积的执行方式,业务执行规模不再与项目经理人数绑定,产能天花板问题得以有效突破。
凭借产品与执行方式上的创新变革,曼孚科技实现了自动驾驶数据标注的规模化量产,从源头端解决了AI应用场景持续拓展对于高质量多源异构数据的海量需求。
随着自动驾驶商业化在更多场景实现落地应用,曼孚科技也将探索更多数据生产与处理的新方式,用高质量数据助力人工智能融合应用走深向实。